Children are phenomenal learning machines, and human learning has long been an inspiration for machine learning and AI. In this project, we are developing novel machine learning methods which are inspired by developmental science. We are also using machine learning tools to gain novel insights into the mechanisms of child development. While developmental ML intersects with standard ML topics such as continual learning, active learning, multi-task learning, etc., most of the key properties of human learners have no analog in current ML technology:
- Human learners must create the tasks which they are solving by deciding what to learn
- Human learners must infer the supervisory signals that guide learning from their environment
- Human learners must learn continuously without the ability to access complete datasets
- Continual visual learning with repetition
- Single image 3D shape reconstruction
- CRIB visual simulator for developmental ML
- Modeling the statistical properties of infant visual object experiences
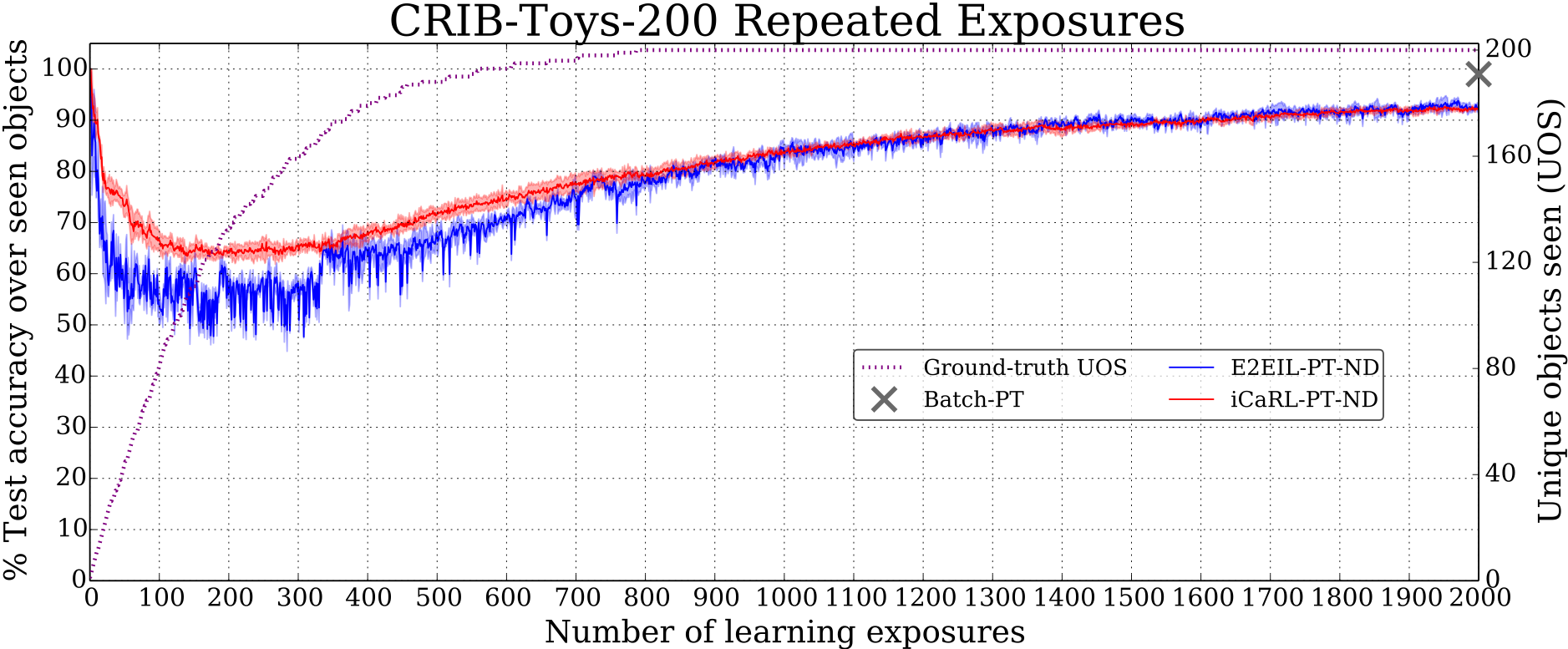
Continual visual learning with repetition
Most work in continual learning adopts a paradigm in which a fixed amount of training data is processed sequentially, so that the learner has a single exposure to each target concept. This approach is focused on addressing catastrophic forgetting, which arises when the representation of a previously-learned concept becomes degraded. However, the single exposure case is highly unnatural. The visual experiences of human and animal learners are defined by repeated exposures to important concept classes. We have demonstrated [1] that the repeated exposures paradigm largely ameliorates the problem of catastrophic forgetting. In this setting, a continual learner with a modest amount of episodic memory can approach the accuracy of batch learning.
Single image 3D shape reconstruction
Children learn to recover properties of 3D object shape well before they acquire facility in object categorization, and experience with shape may enable rapid object learning. The ability to learn 3D object shape from visual inputs is therefore a core building block in developmental approaches to visual learning. We have recently developed a novel architecture, SDFNet [2], for supervised single image 3D shape reconstuction. Given a single RGB image of an object in an arbitrary pose, SDFNet can output a 3D model of the object encoded as a signed distance field.
Our work identified three key issues that affect generalization performance in 3D shape reconstruction: the choice of coordinate representation, the benefit of intermediate representations (depth and normal sketches) and the importance of realistic rendering. The last issue that we investigated regards large-scale evaluation of generalization. We are the first to show that 3-DOF viewer centered coordinate representation experiences no drop in reconstruction performance on novel classes and that there is a significant room for improvement in performance of the 2.5D regressor. We demonstrated that lighting variability and reflectance significantly impact reconstruction performance (0.31 for F-Score@1). We conducted our generalization evaluation on the largest scale to date and outperformed state-of-the-art baselines.






CRIB visual simulator for developmental ML
The creation and validation of computational models of development can be facilitated by access to continous streams of visual imagery which mirror the statistical structured of the visual inputs that infants create during learning. While wearable cameras make it possible to record egocentric video from children in naturalistic settings, such datasets are inherently limited in scope and size. We have taken a first step towards creating a simulator that can generate unlimited amounts of visual data that mirror the types of self-generated visual experiences produced by children during object play.



Modeling the statistical properties of infant visual object experiences
The ability to deploy infant-wearable cameras into the home environment, pioneered by Drs. Linda Smith and Chen Yu at Indiana Univ., has enabled the quantitative characterization of visual experiences in early infancy. The distribution of objects comprising the infant's visual experiences is highly right-skewed, with a small number of categories of familiar objects predominating. Moreover, the names of the objects occurring with high-frequency are among the very first object names that are normatively learned first by infants [3]. These findings suggest that the power law distribution of early object experiences may play a role in facilitating infant object learning. We tested this hypothesis indirectly using a novel iterative machine teaching paradigm [4]. In this approach, a teacher network selects labeled examples to send to student network, with the examples chosen to optimize the student's learning rate. Using labeled egocentric images collected from infants as a training dataset, we compared the statistical properties of object orderings produced by the teaching network to the properties observed in naturalistic infant data. Our findings demonstrate a qualitative similarity between the infant image ordering and the example ordering produced by the teacher.
Personnel
Georgia Tech








External Collaborators




Project Funding
- NSF Awards RI 1320348, BCS 1524565, RAISE 1936970
- Gifts from Xerox PARC and Intel Research
References
- Stojanov, S., Mishra, S., Thai, N. A., Dhanda, N., Humayun, A., Yu, C., Smith, L. B., and Rehg, J. M. (2019). Incremental Object Learning from Contiguous Views. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR 19).
- Thai, A., Stojanov, S., Upadhya, V., Rehg, J. M. (2020). 3D Reconstruction of Novel Object Shapes from Single Images. arXiv preprint:2006.07752.
- Clerkin, E. M., Hart, E., Rehg, J. M., Yu, C., & Smith, L. B. (2017). Real-world visual statistics and infants’ first-learned object names. Phil. Trans. of the Royal Society B: Biological Sciences, 372(20160055), 1–10.
- Liu, W., Dai, B., Humayun, A., Tay, C., Yu, C., Smith, L. B., Rehg, J. M., and Song, L. (2017). Iterative Machine Teaching. In Proc. 34th Intl. Conf. on Machine Learning (ICML 17) (p. PMLR 70:2149-2158).