
The most powerful object recognition systems today do not explicitly make use of object shape during learning. This is despite the widely accepted importance of object shape for recognition, and the evidence for a shape-bias during rapid category learning in both young children and adults. In this work, motivated by recent developments in low-shot learning, findings in developmental psychology, and the increased use of synthetic data in computer vision research, we propose an approach that sucessfully utilizes 3D shape to improve low-shot learning methods' generalization performance to novel classes on multiple datasets. We also develop Toys4K, a new 3D object dataset with the biggest number of object categories that can also support low-shot learning.
Learning an Explicit Shape Bias
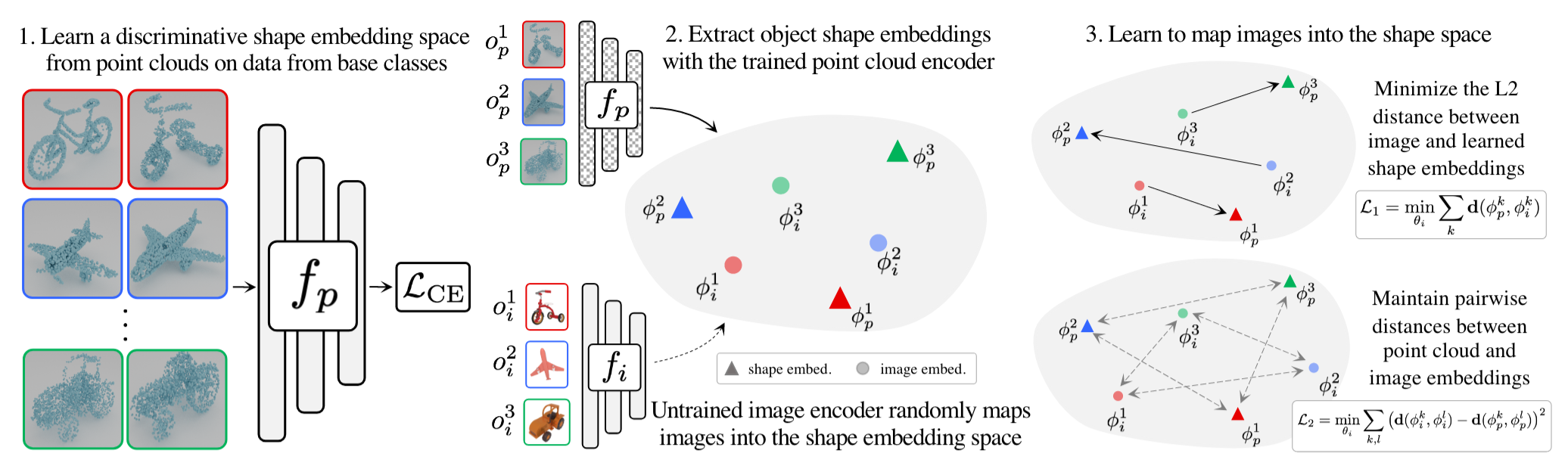
Our main motivation comes from the fact that 3D shape in the form of point clouds allows for better low-shot generalization than images. We aim to utilize this shape-based embedding space by learning how to map images to it. This task is challenging because the image to shape embedding space can only be learned using data from the training classes, but must sucessfuly extrapolate to the novel test classes. To learn this mapping, we optimize the image encoder with respect to two losses: (1) to minimize the distance between image and point cloud embedding pairs, (2) maintain identical pairwise distances between image embeddings and the point cloud embeddings.
Shape Information During the Low-Shot Phase
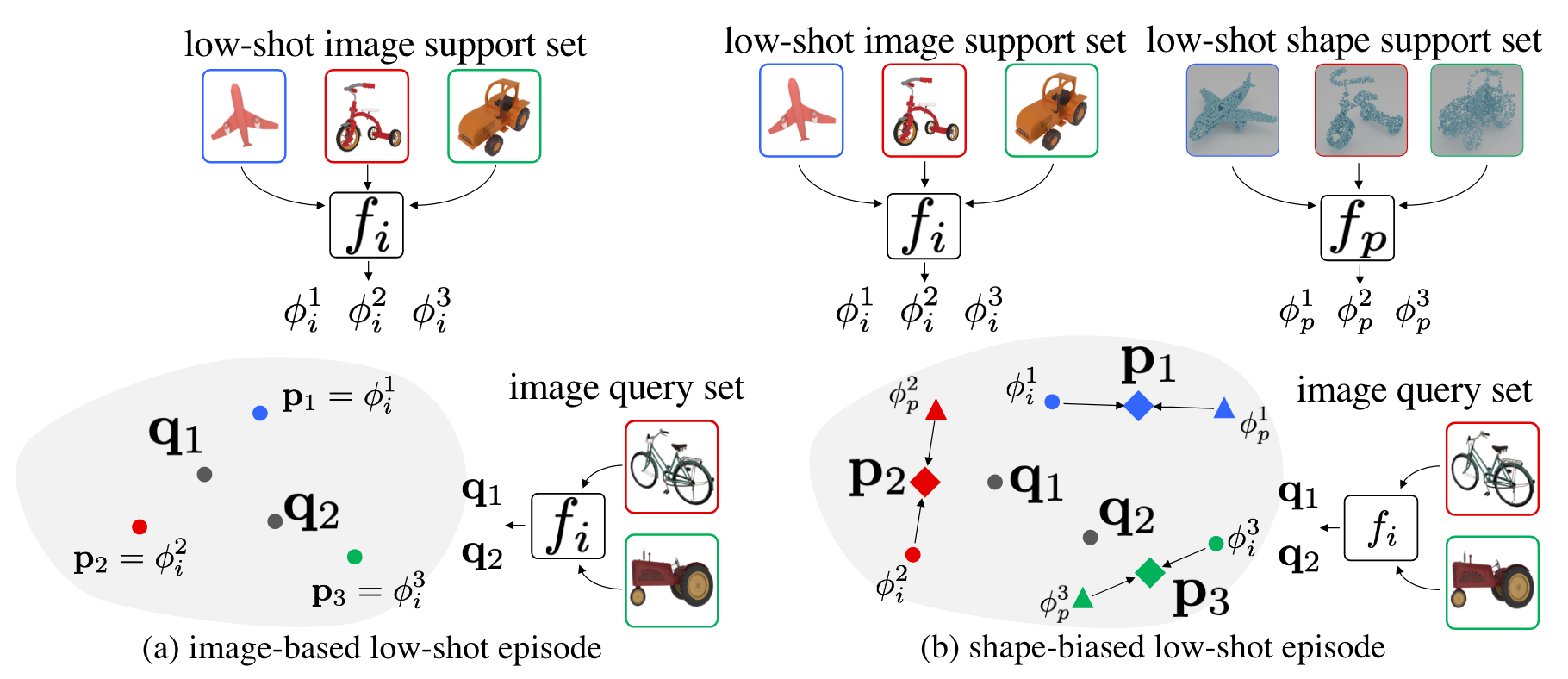
During the low-shot phase, we allow access to object point clouds and images for the shots, and only images for the testing queries. Providing access to shape information at this stage allows for higher quality class prototypes.
Toys4K Dataset

Prior datasets that contain both 2D and 3D information such as ModelNet [1] and ShapeNet [2] have a limited total number of categories and do not focus on covering objects experience by children during development. Our proposed dataset, Toys4K consists of 4,179 object instances in 105 categories, with an average of 35 instances per category. Toys4K is developmentally relevant: The count noun vocabulary size of children, measured using MCDI[3] forms has been found to average of 97 count nouns at 21 months. In Toys4K, 60% of the categories overlap with object nouns that children get tested for in MCDIs.
Results
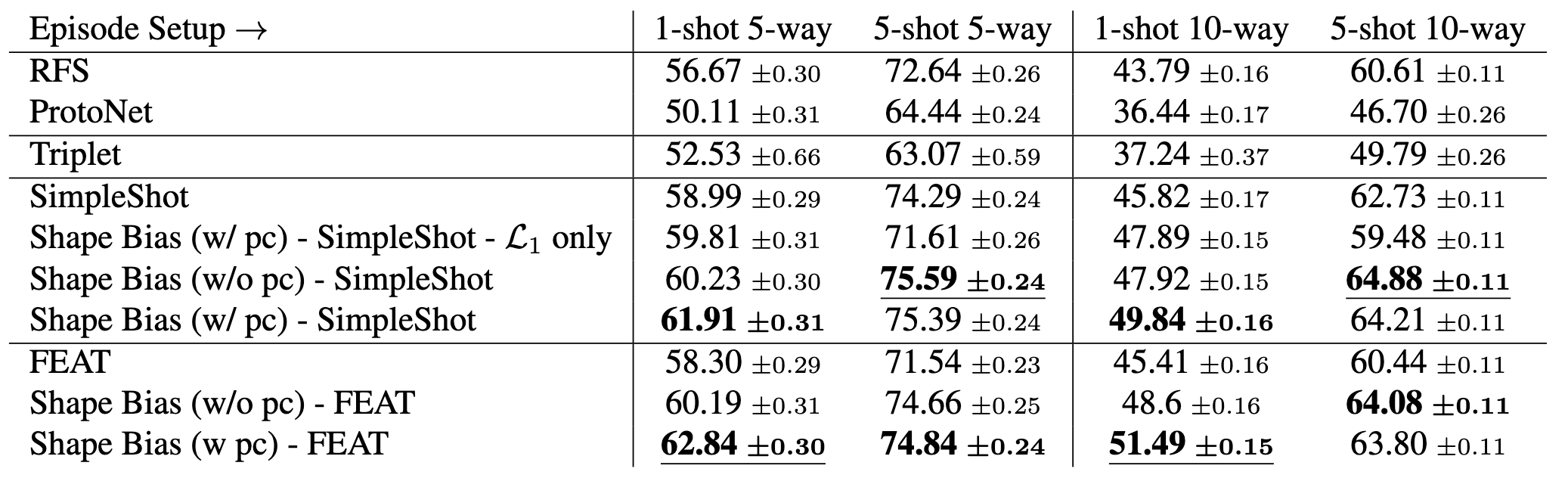
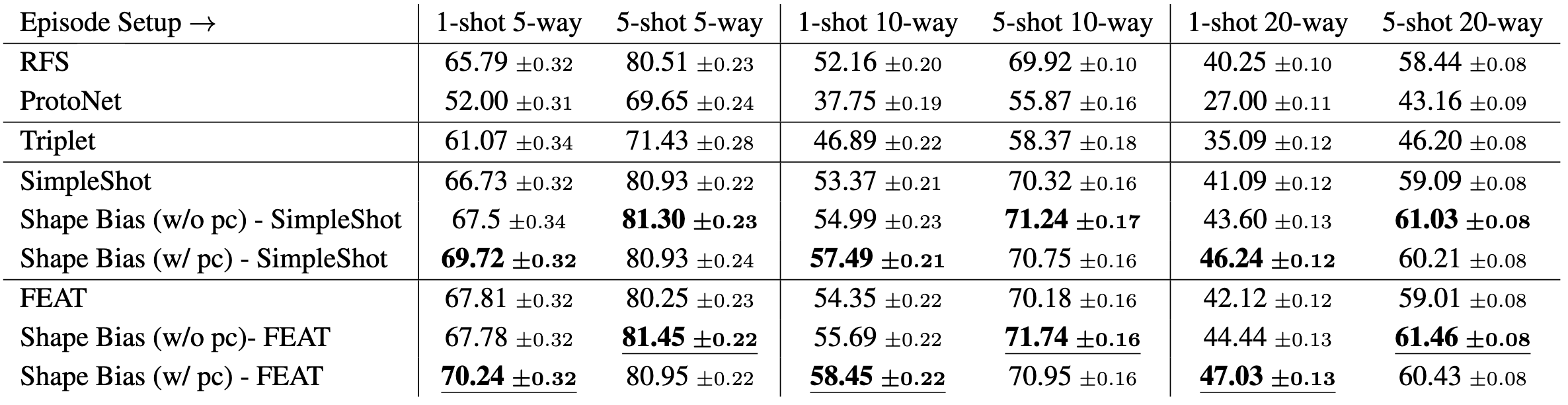
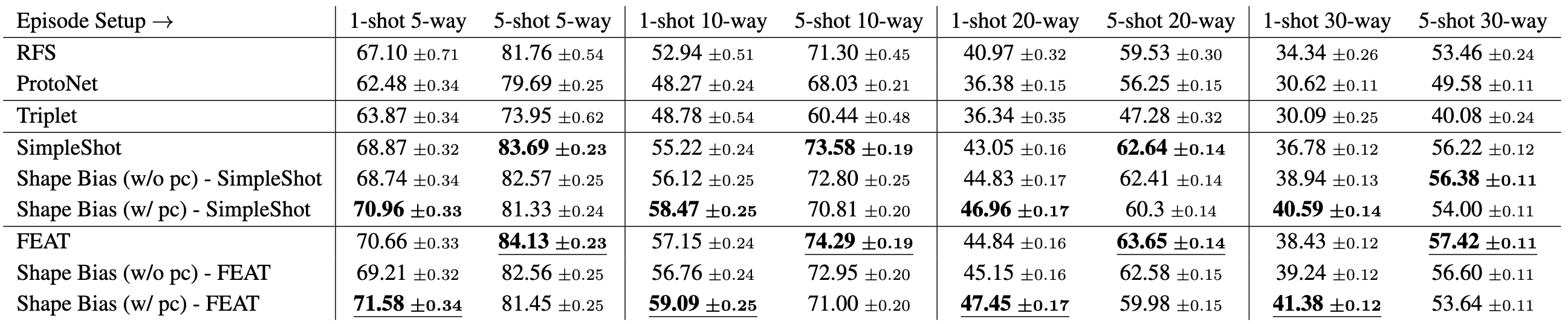
We investigate the benefit of an explicit shape bias by adding it to SOTA low-shot learning methods SimpleShot [4] and FEAT [5] on low-shot training splits for both ShapeNet, ModelNet and Toys4K. We demonstrate that an explicit shape bias results in significant improvements in one-shot learning performance, both when point clouds are available to build class prototypes and when they are not, and results in improved performance relative to multiple image-only baseline algorithms.
Citation
Bibliography information of this work:
Stefan Stojanov, Anh Thai, James M. Rehg 2020. Using Shape to Categorize: Low-Shot Learning with an Explicit Shape Bias arXiv:2101.07296 (2021).
@article{stojanov21cvpr,
title={Using Shape to Categorize: Low-Shot Learning with an Explicit Shape Bias},
author={Stefan Stojanov and Anh Thai and James M. Rehg},
booktitle = {CVPR},
year = {2021}
}
Contact
If you have any questions regarding the paper, please contact sstojanov at gatech dot edu.References
- Wu, Zhirong, et al. "3d shapenets: A deep representation for volumetric shapes." in Proceedings of the IEEE conference on computer vision and pattern recognition. (2015).
- Chang, Angel X., et al. "Shapenet: An information-rich 3d model repository." arXiv:1512.03012 (2015).
- Fenson, Larry, et al. "Variability in early communicative development." in Monographs of the society for research in child development. (1994).
- Wang, Yan, et al. "Simpleshot: Revisiting nearest-neighbor classification for few-shot learning." arXiv:1911.04623 (2019).
- Ye, Han-Jia, et al. "Learning embedding adaptation for few-shot learning." in Proceedings of the IEEE conference on computer vision and pattern recognition. (2015).